

Applied Machine Learning Days 2020 in EPFL are over, and it’s about time we recall our impressions on it. This year the conference featured Edward Snowden and Michal Kosinski as keynote speakers, three conference days and a large variety of tracks. It was really great to see an increasing interest in AI and ML from the industry and catch up on the latest developments. This year AMLD brand will also hold its first ever event abroad – in August at Skoltech, Moscow.
Below are the bits and pieces that we at FAIRTIQ were particularly excited about.

Industry
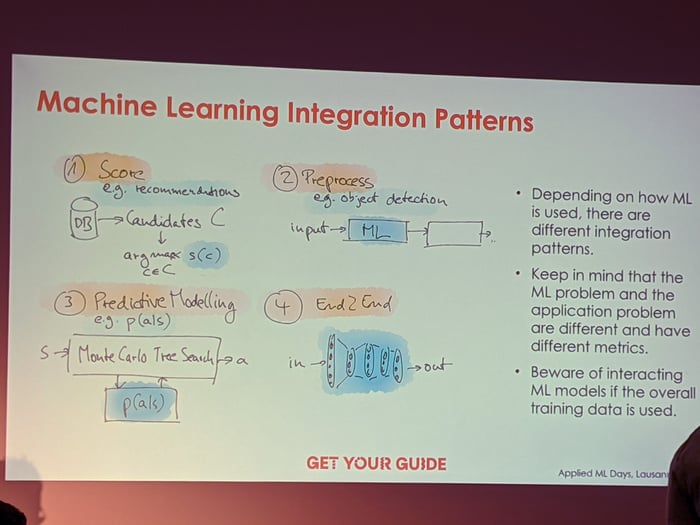
Mikio Braun from GetYourGuide (previously also Zalando) talked about what is missing in bringing ML to production. One of the key elements: designing how ML would be used in the product. There are several ways:
- ML system gives a score to a set of elements that is selected by some other algorithm. Common use case is recommendation systems.
- Preprocessing. ML system is used to pre-process the data that is then used by some other system. For example, detecting cars on a video and then counting them.
- Predictive modelling, where ML system is used to give predications as a part of a larger model, e.g. Monte Carlo Tree Search.
- End-to-end ML system. This is the case for ML systems playing games, e.g. AlphaGo, StarCraft, etc, where the system makes all game decision based on raw input data.
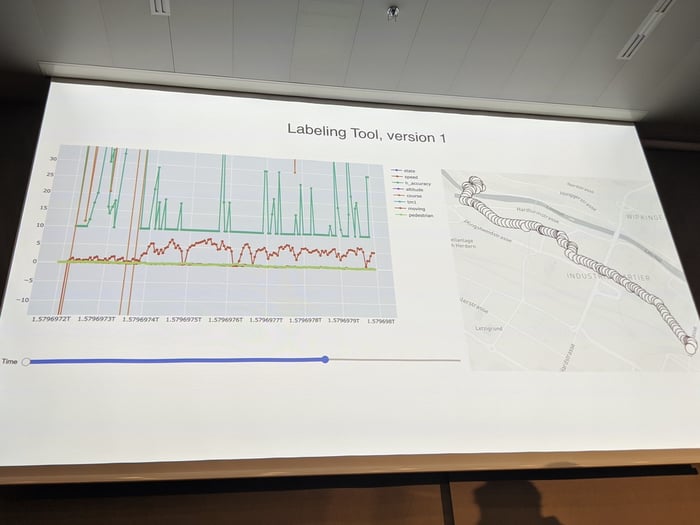
Roger Fischer and Valery Fischer from Datamap presented POSMO (positive mobility) – an app to understand your mobility patterns. The app collects locations and acceleration data that is later classified by a ML system into segments based on your transport mode – train, bus, walk, etc. This is something we are also working on very actively at FAIRTIQ. On the backend, they have developed a really efficient interface to label collected data in order to train the ML model.
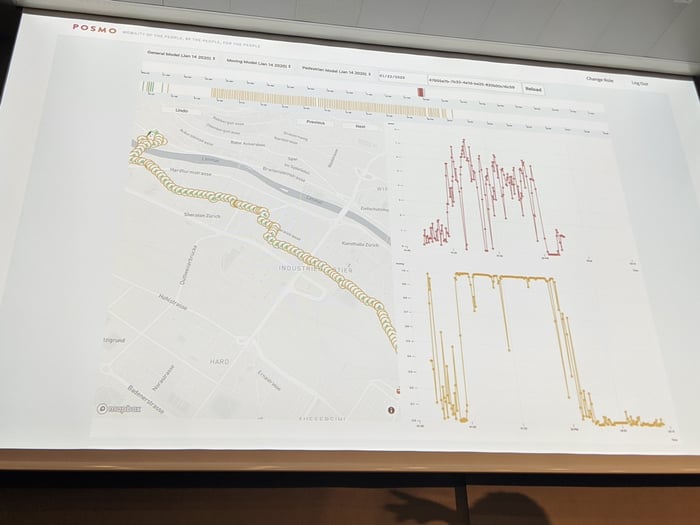
I have also presented our approach to transport mode detection at FAIRTIQ, focusing more deeply on the topics of data collection and labelling, feature engineering and model training.
Kamil Kaczmarek from Neptune.ai talked about TensorCell, an informal group of researchers focusing on using machine learning for city traffic modelling and simulations. I find independent research groups extremely valuable for the society and wish TensorCell all the best in the future work.

David Autor (Ford professor of Economics at MIT) talked about how the development of artificial intelligence and machine learning will affect productivity, the labor market and the distribution of income and wealth in society. He compared the AI/ML revolution to the industrial revolution and the Green revolution (industrialization of agriculture in the beginning of the last century), and made a point that “the future will not take care of itself”, and who benefits from the increase in productivity will be determined in large part by our political choices.

Academic research
Andrey Ignatov (PhD student at ETH Zurich) gave an overview of the ecosystem for running deep-learning models on mobile phones with hardware acceleration. TensorFlow Lite and PyTorch Mobile seem to be the most promising frameworks (no surprise here), although they exhibit certain limitations compared to their desktop counterparts. TensorFlow lite for instance has currently a limited number of operators implemented, so make sure to check the compatibility of your network in this framework while working on desktop.
The increasing GPU power and evolution of ML frameworks drives ML closer to the data source, which is in many cases a mobile phone. This shift has a lot of positive impacts, ranging from apps being able to process data offline to increasing the user’s privacy by keeping the data on the device.
We are also exploring this direction at FAIRTIQ. Our source of data is location data on mobile phone. This information can be very sensitive, so we would like to process it on device when possible.
(related paper DOI: 10.1007/978-3-030-11021-5_19)
Devis Tuia (Professor at Wageningen University) talked about a hybrid system that can understand a range of spatial queries. Currently, location service providers such a Google maps have a limited range of things they can be asked, e.g. a give me information about specific address. But they cannot tell the number of houses in a specific area. Devis presented a system that addresses this problem. It is composed of two networks that are geared towards understanding the question asked by the user (e.g. the number of houses) and the map data that is available (e.g. a satellite view of of Zurich). These networks are then fused to generate a response to the original question.
The use of open data from OpenStreetMap to train the system is particularly elegant. Indeed, OpenStreetMap contain a vast amount of manually curated data, so it is possible to generate virtually infinite number of such spacial question combinations to train an ML model.
(related paper DOI: 10.1109/IGARSS.2019.8898891)
Bonus: event networking apps
Many conferences started using networking apps recently. In 2019 AMLD used Whova application to connect with fellow participants, this year they switch to the Grip application. To me, using the Grip app was a really negative experience, as their Android app had multiple bugs:
- I was not able to filter participants by their interests
- I was not even able to complete my user profile!
Yet another point – Whova allowed to create group discussions – so people could chat and connect by whatever topic – be it industry interests or the language spoken. So I really would like AMLD to come back to Whova.
See you next year!
Big thanks to Jean-Eudes Ranvier and Johannes Josi, Data Scientists on my team for contributing to this post.

-Mar-20-2026-11-47-55-2006-AM.webp?width=732&name=filters_no_upscale()-Mar-20-2026-11-47-55-2006-AM.webp)



Share